What are the most important Clustering Methods in Machine Learning?¶
Clustering is an unsupervised learning where data are grouped into clusters such that members of each cluster are more similar than members of other clusters.
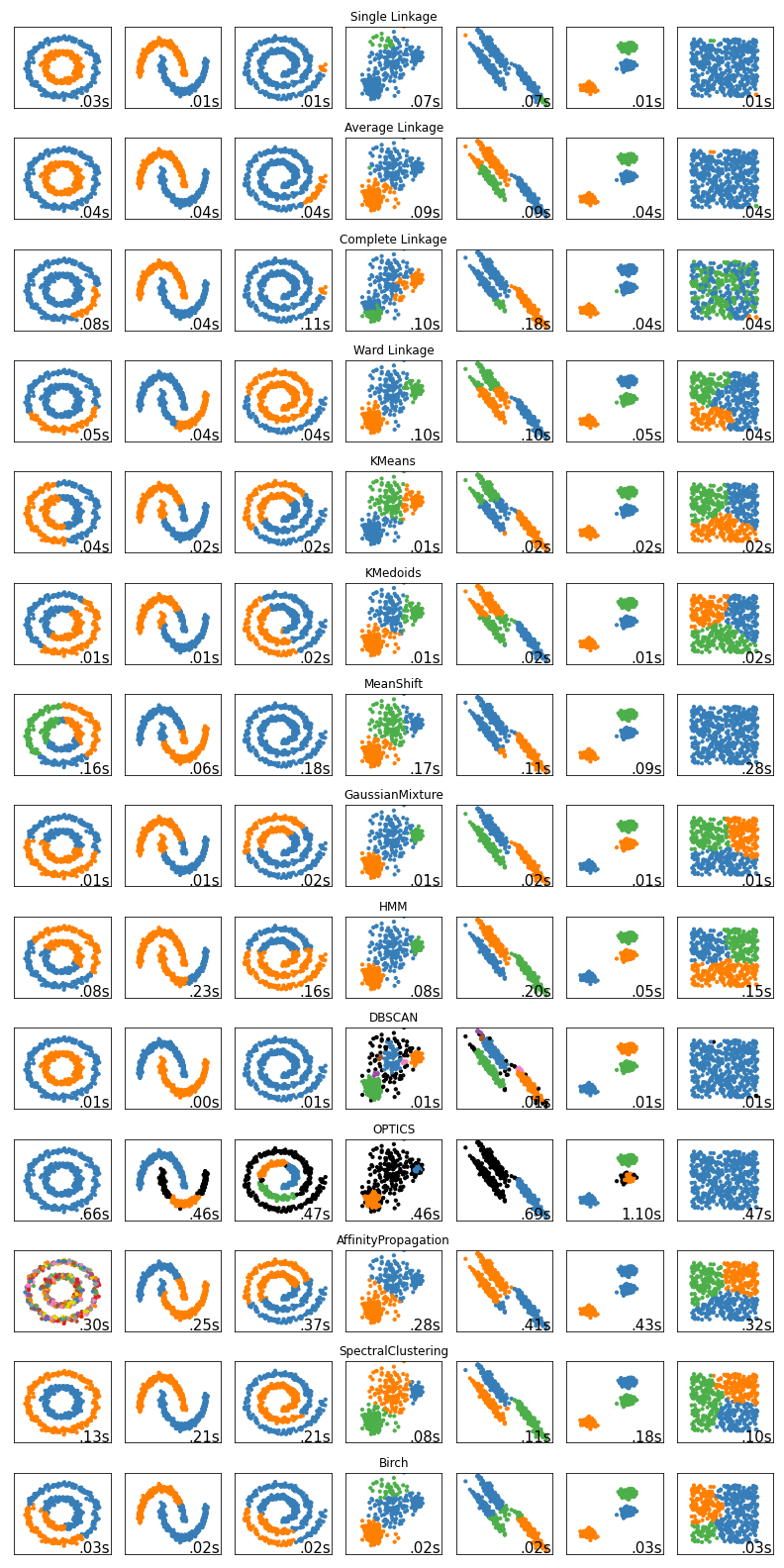
Here we include a brief summary of important clustering methods and a summary chart comparing their results on a set of samples.
Clustering methods can be classified into five major categories: connectivity based, centroid based, distribution based, density based and other methods.
Connectivity based (Hierarchical Clustering)
Connectivity based or Hierarchical clustering build clusters on a successive manner either on a bottom up merging (agglomerative) or top down splitting (divisive). The choices on distance function and linkage criterion needs to be made.
In Agglomerative Clustering, we start from each element being a cluster and successively merge the closest ones. The choice of how the distance is computed between two clusters results in various subtypes: Single Linkage (distance between closest elements of pairs of clusters), Complete Linkage (distance between farthest elements of pairs of clusters), Average Linkage (average distance between elements of pair of clusters). Ward is a particular case where the sum of squared distances between elements with all clusters is minimized.
Centroid based
Centroid based clustering is done by an optimization to find k centers for the clusters and assigning the objects to the closest cluster centers. The variations are based on how the cluster centroid is determined (K-Means uses mean of elements whereas K-Medians uses the median of elements), restricting the centroid to be a member of the dataset (K-Medoids), or allowing a fuzzy cluster assignment (Fuzzy C-Means). In particular Mean Shift Clustering is done by shifting the mean towards a region of the maximum increase in the density of the points and automatically decides on the number of clusters.
Distribution based
Distribution based clustering defines clusters as elements most likely belonging to a distribution. Gaussian Mixture Models are a prominent type of distribution based clustering where Gaussian distributions are used to fit the data. Hidden Markov Model is a system based on Markov process with hidden states where the state transitions and emission probabilities are optimized. The main difficulty with HMM is that there is no known algorithm to find the global optima and multiple initializations are needed to select higher score model.
Density based
Density based clustering methods find clusters as areas with higher densities often leaving elements in low density areas as noise. DBSCAN as one of the popular density based methods, operates based on concept of density reachability. It finds and extends the cluster based on minimum number of elements within a given range parameter. OPTICS, however removes the need for specifying the range parameter.
Other Methods
Affinity Propagation builds clusters by sending messages between pairs of samples containing information on how representative is one sample of the other until convergence. These messages are updated based on information retrieved from other elements. Spectral Clustering functions based on application of base clustering methods on the relevant eigenvectors of the Laplacian of similarity matrix. Similarity matrix is a symmetric matrix representing the similarity between each pair of elements. Birch builds a tree called Clustering Feature Tree (CFT) on an iterative manner where each node has a number of subclusters and each subcluster can have further subnodes with subclusters. On introduction of a new sample, the appropriate subcluster is identified for the new sample and the tree structure is updated.
Comparison
The chart below demonstrates the results of various methods on a number of clustering samples.