What are various methods in Model Free Reinforcement Learning?¶
Different methods in Model Free Reinforcement Learning leverage on one or both of Policy Optimization and Q-Learning. In Policy Optimization the parameters specifying the policy are tuned to arrive at an optimal policy, whereas in Q-Learning the action-value function is optimized.
Policy Optimization
Policy Gradient
In Policy Gradient, the policy is updated based on the gradient of the expected return. The gradient is estimated based on set of trajectories that are obtained by running the policy.
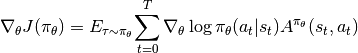
Actor-Critic
Actor-Critic refers to the family of approached that during the policy optimization, either action or state value function is also learned. In A3C for example, the state value is learned and used as the baseline for the policy gradient update.
Proximal Policy Optimization (PPO) & Trust Region Policy Optimization (TRPO)
In both PPO and TRPO, the policy is updated to maximize the surrogate advantage. In PPO, the optimization is penalized by distance between the current policy and the updated policy while in TRPO, the KL divergence between the current and the updated policy is constrained.
Q-Learning
Deep Q Network (DQN)
In DQN, a neural network is used to learn the
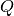 value function and experience play and periodically updated target are used to improve and stabilize the training. Here, the action is picked based on maximum value, and the value is updated based on the observed reward based on the following equation where
value function and experience play and periodically updated target are used to improve and stabilize the training. Here, the action is picked based on maximum value, and the value is updated based on the observed reward based on the following equation where 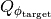 is copied from the main network every fixed-number-of-steps.
is copied from the main network every fixed-number-of-steps.
Hindsight Experience Replay (HER)
In HER, a set of additional goals are added such that the replayed trajectories have either the original goal or one of the alternative goals. HER helps to speed up the convergence particularly in the presence of sparse rewards.
Combination of Policy Optimization & Q-Learning
Deep Deterministic Policy Gradient (DDPG)
In DDPG, the
value is updated similar to DQN and the policy is updated based on: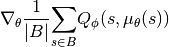
here
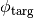 and
and 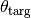 are updated based on:
are updated based on: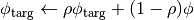
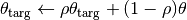
Twin Delayed DDPG (TD3)
TD3 is enhanced version of the DDPG to address the issues with hyperparameter tuning and Q-value overestimation. The algorithm learn two Q functions concurrently and uses whichever gives a smaller target value. The policy and target networks are updated less frequently and finally noise is added to the target action to avoid exploitation of Q function errors by the policy.
Soft Actor-Critic (SAC)
SAC builds on the central idea of entropy regularization and optimizes the policy to achieve a balance between expected return and policy entropy. Value function and action-value function are redefined to include the entropy reward. Update of the Q-function and policy are similar to TD3 with exception of addition of the entropy terms, the next state actions coming from the current policy and absence of explicit target policy smoothing.